



最近更新
阅读排行
- 03/15方差分析是什么?怎么...
- 04/18了解学慧网健康管理师...
- 04/17湖南省健康管理师报考...
- 04/12如何快速查询执业药师...
- 04/03主管护师一般考的什么...
- 04/03主管护师有什么好处
- 04/03考主管护师需要什么材...
- 04/03什么时候可以报考主管...
- 04/03主管护师大纲2024...
- 04/03主管护师的报考条件是...
- 09/08auc医学上什么意思
- 09/05医生职称等级划分标准...
- 09/05规培医生是什么意思啊
- 09/13医生规培是什么意思?
- 02/022023年执业药师继...
- 10/09医学检验技术和医学检...
- 09/16民营医院是私立医院吗
- 02/20湖南医考网:医师实践...
- 09/05医生的职称等级划分
- 09/08发生职业暴露后的处理...
推荐公司
急招岗位










方差分析是什么?怎么使用?
时间:2023-03-15 20:03
对总体均值的假设检验,有三种情况:
1、总体均值与某个常数进行比较;
2、两个总体均值之间的比较;
3、两个以上总体均值之间的比较;
对于前两种情况,用Z分布和T分布就能快速得到假设检验结果。如果比较的总体大于三个,继续用它们也能够得到比较结果,只是需要两两比较,耗时耗力。这种情况下,使用方差分析能够一次性比较两个及两个以上的总体均值,看看它们之间是否有显著性差异。常用的方差分析方法包括:单因素方差分析、多因素方差分析、协方差分析、多元方差分析、重复测量方差分析、方差成分分析等。
方差分析原理
方差分析的原理通俗的解释就是将试验数据的总离散分解为来源于不同因素的离散,并作出数据估计,从而发现各个因素在总离散中所占的重要程度。方差分析原理的推导过程可以回顾:方差分析:单因素方差分析,在这篇文章中以单因素方差分析为例,完整介绍了方差分析的公式推导过程,今天主要介绍方差分析的几个比较难以理解的地方。
名词解释
因素:方差分析的研究变量;例如,研究裁判打分的差异,裁判就被称为因素;
水平:因素中的内容称为水平;例如,总共有3个裁判打分,则裁判因素的水平就是3;
观测因素:又称观测变量,指对影响总体的因素;
控制因素:又称控制变量,指影响观测变量的因素;
假设检验原理
以单因素方差分析为例,介绍方差分析原理,下图是单因素方差分析表格。
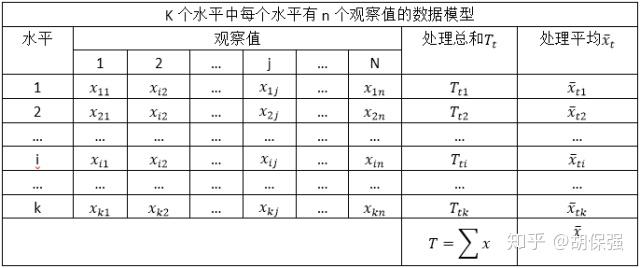
表格中有k个水平,表示单个因素(变量)有k种情况,将数据分成为k组,每行为一组。根据这个表格,可以计算得到三个方差:总方差,组间方差和组内方差,总方差等于组间方差加上组内方差。组内方差代表的是偶然因素造成的数据差异;组间方差代表的是因素的不同水平造成的数据差异。
如果单个因素的不同水平对于数据总体没有影响,那么组间方差与组内方差没有显著性差异;如果单个因素的不同水平对于数据总体有影响,组间方差和组内方差就会有显著性的差异。用组间方差除以组内方差,得到F值,F值的分布服从F分布,所以F值在F分布上有对应的显著概率p值。当p值大于假设检验的显著性水平时,说明组间方差和组内方差没有显著性差异,也就是说因素的不同水平对于数据总体没有影响;反之,当p值小于假设检验的显著性水平,说明因素的不同水平对于数据总体有影响。
假定条件
1、多个样本来自的多个总体是正态分布的。方差分析运用的是F分布,只有服从正态分布的总体才适用F分布进行假设检验,否则,检验结果是没有意义的。
2、单个因素的不同水平分组的方差要求齐性。前面介绍了,方差分析假设的是单个因素的不同分组数据之间没有区别,换一种说法就是单个因素的不同分组对于数据总体没有影响,也就是说不同分组的数据都来自同一个数据总体,方差相同。
基于以上两个假设,方差分析才能将方差的差异性推断转换成对两个以上总体均值的差异性推断。
事后多重比较
经过方差分析以后,如果检验结果显示多个水平之间存在显著性差异,那么还需要进行事后多重比较。因为方差分析结果的显著只能说明两个以上总体的均值之间存在显著性,但是不能分析出具体是那几个总体的均值不相等,所以还需要进行两两总体均值的比较。
方差分析步骤
1、方差齐性减压;
2、计算各项平方和与自由度;
3、列出方差分析表,进行F检验,并依据F值对应的p值做出判断;
4、事后多重比较;
方差分析模型
方差分析的基本思路是将数据波动(变异)分解为若干部分,除了有一部分代表随机误差,其余每个部分的变异分别代表了某个影响因素的作用(包括交互作用形成的因素)。通过比较因素所致的变异与随机误差的大小,借助F分布和F统计量做出推断:该因素对因变量的影响是否显著存在。F统计量=组间方差/组内方差。
以上是方差分析的基础,下面我们用函数模型对上面的的思路进行解释,你会发现是另一番景象。为了更好理解,我们引入一个例子进行说明:假设现在要比较三种职业的月收入有无差异,这三种职业分别是医生、律师和软件工程师。
在这三类人群中进行随机抽样,各自得到一组受访者,采集他们的月收入数据,然后进行检验。每位受访者的收入数据可以表示为:

需要注意,随机误差通常服从均值为0的正态分布,这是很多数据分析过程的基础。为了对三种职业的收入是否相等做出判断,上式有被改写成下面的形式:

这样就将方差分析思路用函数模型的形式表示出来了,我们称之为方差分析模型。现在定义医生为第一种职业,且a1=2000,表示医生这个职业对平均月收入有影响,使平均月收入提高了2000元。如果三种职业的平均月收入不相等,那么三种职业对总平均月收入的影响是不相等的,有a1不等于a2不等于a3;反之,则三种职业对总平均月收入的影响完全相等。判定的量化依据就是三种职业的影响力差距ai与随机误差的比值。
拓展单因素方差分析模型,多因素方差模型可以表示为:

上面的式子表示无交互作用的多因素方差分析模型,下面的则代表有交互作用的多因素方差分析模型(交互因素没有写全)。
以上内容就是方差分析模型的建立思路。将方差分析用模型的形式理解以后,我们就可以使用回归分析的方法对模型进行解释,得到包含更多信息含量的结果。方差分析模型的解析过程将在后面逐步介绍,这些都有助于你理解和使用SPSS进行更为高级的分差分析。
方差分析模型常用术语
因素与水平
因素也被称为因子,就是指可能对因变量有影响的分类变量,而分类变量的不同类别就被称为水平。显然,一个进入分析的因素会有不止一个水平,例如,性别有男、女两个水平,而分析目的就是考察或比较各个水平对因变量的影响是否相同。在方差分析中,因素的取值范围不能无限,只能有若干个水平,但需要注意的是有时候水平是人为划分出来的,比如身高被分为高、中、低三个水平。
水平组合
指各因素各个水平的组合,例如,在研究性别(二个水平)和血型(四个水平)对成年人身高的影响时,最多可以有2*4=8个水平组合。
协变量
协变量指对因变量可能有影响,需要在分析时对其作用加以控制的连续型变量。因素和协变量分别为分类变量和连续型自变量。当模型中存在协变量时,一般是通过找出它与因变量的回归关系来控制其影响。
交互作用
如果一个因素的效应大小在另一个因素不同水平下明显不同,则称两个因素间存在交互作用。当存在交互作用时,单纯研究某个因素的作用是没有意义的,必须区分另一个因素的不同水平研究该因素的作用大小。如果所有单元格内都至多只有一个元素,则交互作用无法进行分析,只能不予考虑。
固定因素与随机因素
固定因素指的是该因素在样本中所有可能的水平都出现了。换言之,该因素的所有可能水平仅此几种,针对该因素而言,从样本的分析结果中就可以得知所有水平的状况,无需进行外推。比如要研究三种促销手段的效果有无差别,所有样本只会是三种促销方式之一,不存在第4种促销手段的问题,则此时该因素就被认为是固定因素。随机因素指的是该因素所有可能的取值在样本中没有全部出现。换言之,目前在样本中的这些水平是从总体中随机抽样而来,如果重复本研究,则可能得到的因素水平会和现在完全不同,这时,研究者显然希望得到的是一个能够“泛化”,即对所有可能出现的水平均适用的结果。例如研究广告类型和投放的城市对产品销量是否有影响,在设计中随机抽取了20个城市进行研究,显然,研究者希望分析结果能够外推到全国的所有大、中型城市,此时就涉及将结果外推到抽样未包括的城市中的问题,在这种情况下,城市就应当是一个随机因素。
登录查看全部内容
信息来源于网络,如有侵权,请联系我们,及时删除,如有变更请以原发布者为准。

注册/登录获取更多内容
获取验证码



 客服
客服 小程序
小程序

 公众号
公众号

 工具箱
工具箱



